
在深度学习的应用中,模型微调(fine-tuning)是一个非常重要的过程,它是指在一个预先训练好的模型上针对特定的任务进行参数调整。常见的微调方法有:Adapter Tuning、LORA、Prefix-Tuning、Prompt Tuning、P-tuning、P-tuning v2,文章将分两次介绍这几种微调方法。
一、Adapter Tuning
1.1 原理
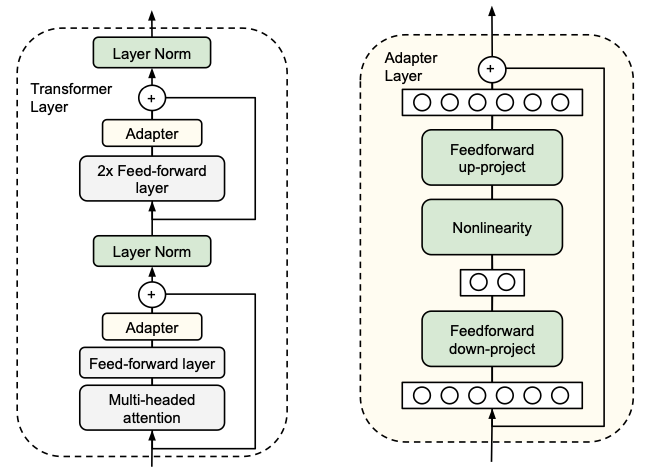
设计了Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将 Adapter 设计为这样的结构:
-
首先是一个 down-project 层将高维度特征映射到低维特征
-
然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征
-
同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为identity(类似残差结构)
1.2 效果
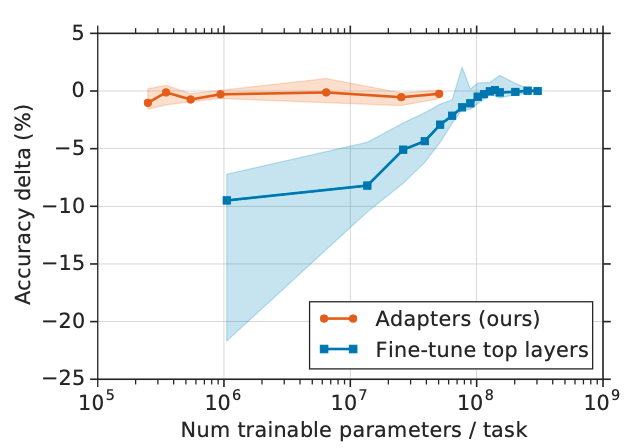
能够在只额外对增加的 3.6% 参数规模(相比原来预训练模型的参数量)的情况下取得和Full-Finetuning 接近的效果(GLUE指标在0.4%以内)。
1.3意义与遗留问题
首次提出针对 BERT 的 PEFT微调方式,拉开了 PEFT 研究的序幕。
遗留问题:增加了模型层数,引入了额外的推理延迟。
二、LORA
2.1 原理
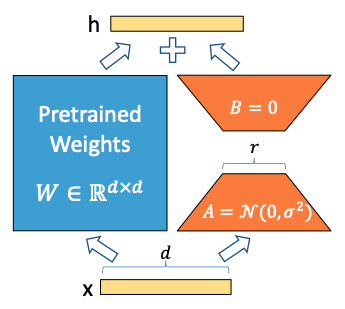
LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
-
在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的
intrinsic rank。 -
训练的时候固定 PLM 的参数,只训练降维矩阵 A 与升维矩阵 B 。而模型的输入输出维度不变,输出时将 BA 与 PLM 的参数叠加。
-
用随机高斯分布初始化 A ,用 0 矩阵初始化 B ,保证训练的开始此旁路矩阵依然是 0 矩阵。
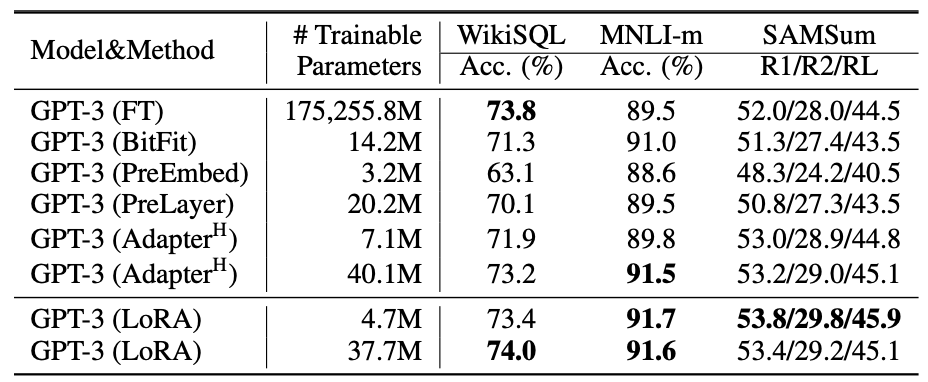
2.2效果
LORA 相比其它微调方法,增加参数量不会导致性能的下降。
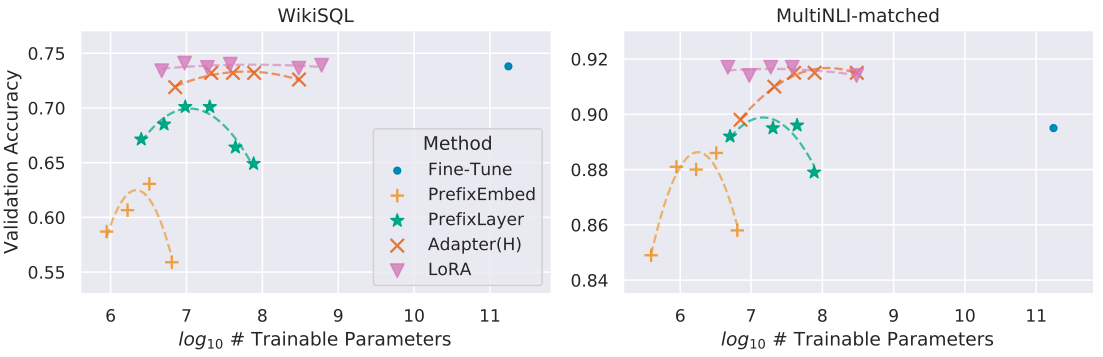
性能上与全参数微调持平甚至超过。
2.3意义与遗留问题
基于大模型的内在低秩特性,增加旁路矩阵来模拟全参数微调,LoRA 将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。
GPT 的本质是对训练数据的有效压缩,从而发现数据内部的逻辑与联系,LoRA 的思想与之有相通之处,原模型虽大,但起核心作用的参数是低秩的,通过增加旁路,达到四两拨千斤的效果。
三、Prefix-Tuning
3.1原理
与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。
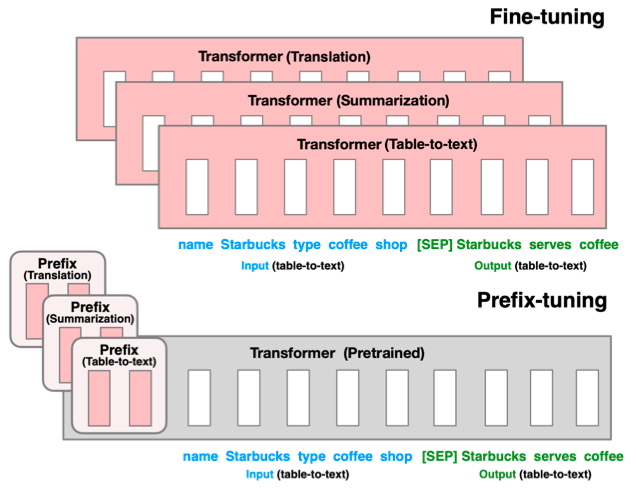
同时,为了防止直接更新 Prefix 的参数导致训练不稳定的情况,他们在 Prefix 层前面加了 MLP 结构(相当于将Prefix 分解为更小维度的 Input 与 MLP 的组合后输出的结果),训练完成后,只保留 Prefix 的参数。
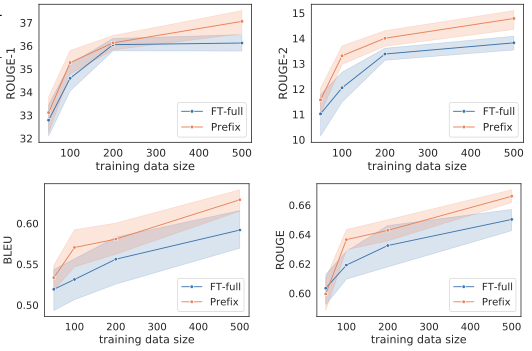
3.2 效果
表明Prefix-tuning能用更少的参数达到较有竞争力的结果。在Low-data阶段(训练样本数较少), prefix-tuning相比较fine-tuning更有优势。
3.3 意义与遗留问题
遗留问题:难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能。
本节介绍了 Adapter Tuning、LORA、Prefix-Tuning这三种大模型微调方法,在下节内容会介绍其他三种微调方法。Prompt Tuning
原理
Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。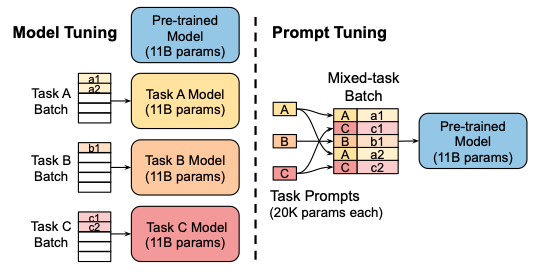 固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt tuning。
固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt tuning。效果
似乎只要预训练模型足够强大,其他的一切都不是问题。作者也做实验说明随着预训练模型参数量的增加,Prompt Tuning的方法会逼近 Fine-tune 的结果。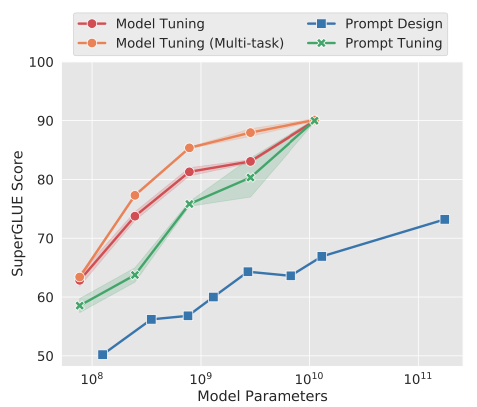
意义与遗留问题
该方法可以看作是 Prefix Tuning 的简化版本,Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。遗留问题:由人工设计Prompt,自然语言提示本身十分脆弱(如下图所示,选择不同的Prompt对下游任务的性能影响较大),而且从优化角度无法达到最优。P-tuning
原理
Prefix Tuning 的简化版本,只在输入层加入 prompt tokens,并不需要加入 MLP 进行调整来解决难训练的问题,主要在 T5 预训练模型上做实验。固定预训练参数,为每一个任务额外添加一个或多个 embedding,之后拼接 query 正常输入 LLM,并只训练这些 embedding。左图为单任务全参数微调,右图为 Prompt tuning。效果

意义与遗留问题
遗留问题:Prompt Tuning和P-tuning这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning类似的效果,而参数规模较小时效果则很差,且在sequence tagging任务上表现都很差。P-tuning v2
原理
相比 Prompt Tuning 和 P-tuning 的方法, P-tuning v2 方法在多层加入了 Prompts tokens 作为输入,带来两个方面的好处:带来更多可学习的参数、足够 parameter-efficient,同时加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。v1 到 v2 的可视化:蓝色部分为参数冻结,橙色部分为可训练部分。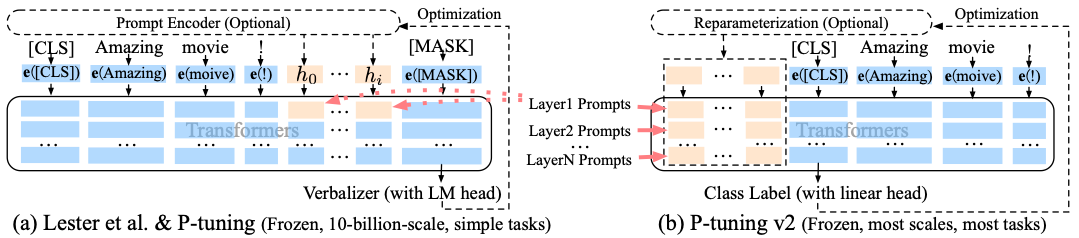
效果
遗留问题
很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差。